The challenge
A few days ago I saw a tweet from my friend saying:
That feeling when you process 5,275,521 records from #JSON to #MySQL in 43 minutes thanks to @celeryproject and @sqlalchemy! #Python
—@ProfFalken
My first thought was: great! The second one was… that doesn’t sound like a lot, I bet I could make it faster! So I took the challenge after requesting the original source.
The app contains two parts. The first one reads the file (1 JSON per line) and pushes pre-processed data to a message queue. The second one takes the items from the queue, pushes some to the database and creates a few more queue messages. In practice it’s using Redis and MySQL, but that’s not very relevant in this case.
Parsing
The first part doesn’t do a lot of processing, so I was expecting the runtime to be dominated by waiting for the queue writes. But that’s not what happened. The time was split between sending messages (55%) and parsing JSON (37%) and that seemed very wrong. Python profiler and gprof2dot provide a good explanation of why that happened. You can easily see on the graph that json.loads has three places where it’s called, even though we only have one place that reads the file. This was easily fixed by parsing the line only once and passing on the resulting dict instead.
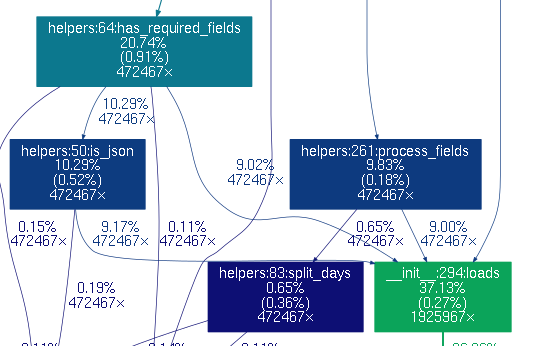
This resulted in a much better split (76% / 17%). Rejecting some lines even before parsing (because they didn’t include the required keyword) helped a bit too (78% / 14%). This resulted in ~20% time saving on the file processing part - good, but not amazing.
Queue processing
The second part was a bit more interesting. The workers should be either CPU or disk bound, repackaging the data into a format ready to insert to the database and then handing it off to MySQL. But it was neither. It was mostly just waiting for the queue, network, and context switching. That means both the disk and the CPU were underutilised.
To improve the situation, the app needs to do more work while its process is active. This applies to all the layers - reading messages, processing them, and the database writes.
The tweak for reading messages is already built-in. CELERYD_PREFETCH_MULTIPLIER configuration option is available and allows reading more than one message at a time. For long running tasks and small messages, it may not make sense to prefetch more than one item. But for tiny tasks, prefetching more items allows us to get higher throughput. In this case, I just increased the prefetch until diminishing returns started showing. Now, the CPU utilisation went up from 10% to 25% in each of 4 workers. Better, but not great.
The next part was processing the requests. Instead of running the function for each item, we can tell celery to schedule multiple items at the same time. This can be done using celery.contrib.batches. Increasing the batch size with flush_every improved the throughput a little bit. Maybe it just caused the acknowledgements to be sent in one series? The important part is that it allowed the next optimisation to work.
Finally, the biggest gain was batching the inserts into the database. This was only possible due to the previous two fixes. Almost all drivers in SqlAlchemy allow you to do bulk inserts of data, which means the multiple rows are inserted in one command, cutting down unnecessary communication. Switching to bulk inserts actually allowed to move the bottleneck from the queue worker to the database.
When generating the data for this graph, the batch size was adjusted both for the queue and for the database inserts at the same time. It shows that with 4 processes the performance doesn’t really raise after a batch of 10 items, and with 2 processes after a batch of around 17. For a more complex task, there could be a tradeoff to consider due to multiple unacknowledge items being processed at the same time. If the operations are not completely idempotent, crashing with more items means more emergency cleanup. In this case the batch size doesn’t really matter. Either the rows are going to be inserted or not - duplicates are easy to detect and ignore.
The great thing about 2 workers maxing out the performance in this case is that just by using bigger batches, the workers can saturate the database writes, leaving 2 out of my 4 CPU cores available for other tasks. The other thing to notice is that adjusting the batch size effectively allowed 6x performance gain, with mostly cosmetic code changes.
Summary
Processing in batches is awesome. If done properly, it cuts down unnecessary network traffic, context switches, disk seeking, and other things that stop your app from achieving maximum throughput.